hadoop(一)--双节点集群搭建 (原创)
发布时间:2018-06-23 09:45:29 文章分类:hadoop 阅读(981) 评论(0)
虚拟机:2台,centos6.5 x86_64系统
hadoopNode01 192.168.9.11
hadoopNode02 192.168.9.12
jdk:jdk-7u80-linux-x64.tar.gz (7系列的最后一个版本)
hadoop: hadoop-2.7.6.tar.gz (2.7系列的最后一个版本)
远程客户端: secureCRT软件 SecureCRTPortable.zip(绿色版)
(百度云盘 链接:https://pan.baidu.com/s/14RwoIsy8VvGQ55fWScahbw 密码:cquv)
二、开始安装CentOS
注意:安装时,可以先安装好一台虚拟机,然后再使用vmware的克隆功能克隆出一个一模一样的vm机(克隆后的vm机需要修改下ip和mac地址)
下面开始正式安装步骤:
1、安装vm机,安装过程中创建一个普通用户 hadoop,密码hadoop。语言:简体中文,地区:亚洲/上海。
2 、配置ip 网关,主机名等
ip 、掩码 、网关 为: 192.168.9.11 255.255.255.0 192.168.9.2
sudo vi /etc/sysconfig/network-script/ifcfg-eth0 ,修改内容如下:
DEVICE=eth0 HWADDR=00:0C:29:1D:AF:54 TYPE=Ethernet UUID=cc7dcfc2-c331-440e-a903-3aca72fb22d6 ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static IPADDR=192.168.9.11 NETMASK=255.255.255.0 GATEWAY=192.168.9.2 DNS1=114.114.114.114 DNS1=8.8.8.8service network restart 重启网络服务使之生效.
修改主机名 hostname hadoopNode01
sudo vi /etc/sysconfig/network ,修改内容如下
NETWORKING=yes #HOSTNAME=localhost.localdomain HOSTNAME=hadoopNode01 NTPSERVERARGS=iburst
3、 修改host文件 ,vi /etc/hosts 修改如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.9.11 hadoopNode01 192.168.9.12 hadoopNode02reboot 修改主机名需要重启下,使之生效。
4 、 安装jdk (安装路径 /home/hadoop/app/jdk1.7.0_80)
cd installpkg/
tar -zxvf jdk-7u80-linux-x64.tar.gz -C ../app/
sudo vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_80 CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME export PATH export CLASSPATH
su root
source /etc/profile 使之生效
三、安装hadoop-2.7.6
cd installpkg/
tar -zxvf hadoop-2.7.6.tar.gz -C ../app/
修改hadoop的etc中的几个配置文件。
1、hadoop-env.sh 修改
vi hadoop-env.sh ,直接设置JAVA_HOME 环境变量的值
exprt JAVA_HOME =/home/hadoop/app/jdk.1.7.0_80
2、core-site.xml 修改
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopNode01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.6/tmp</value>
</property>
</configuration>
cd /home/hadoop/app/hadoop-2.7.6
mkdir tmp
2、hdfs-site.xml 修改
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
3、mapred-site.xml 配置文件修改
mv mapred-site-template.xml mapred-site.xml
vi mapred-site.xml
<configuration>
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4、 修改yarn-site.xml 配置文件
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopNode01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5 修改 slaves配置文件
hadoopNode01 hadoopNode02
6 、修改/etc/profile 文件 ,加上hadoop环境变量
JAVA_HOME=/home/hadoop/app/jdk1.7.0_80 CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar HADOOP_HOME=/home/hadoop/app/hadoop-2.7.6 PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME export HADOOP_HOME export PATH export CLASSPATH四、克隆hadoopNode01虚拟机 到hadoopNode02虚拟机
注意:克隆时选择克隆当前状态、完整克隆
克隆完成后,需要修改下新克隆出的机器(hadoopNode02)的ip和mac地址 。
再重启网络服务 service network restart,
修改主键名hostname,重启虚拟机。
五、 配置hadoopNode01、hadoopNode02 之间相互的免密登录。
hadoopNode01 上:
ssh-keygen -t rsa
ssh-copy-id hadoopNode01
ssh-copy-id hadoopNode02
hadoopNode02 上:
ssh-keygen -t rsa
ssh-copy-id hadoopNode01
ssh-copy-id hadoopNode02
六、启动hdfs 集群
hadoopNode01 上执行:
start-dfs.sh 此命令会启动本机上namenode 、datanode、secondarynamenode 和hadoopNode02上的datanode
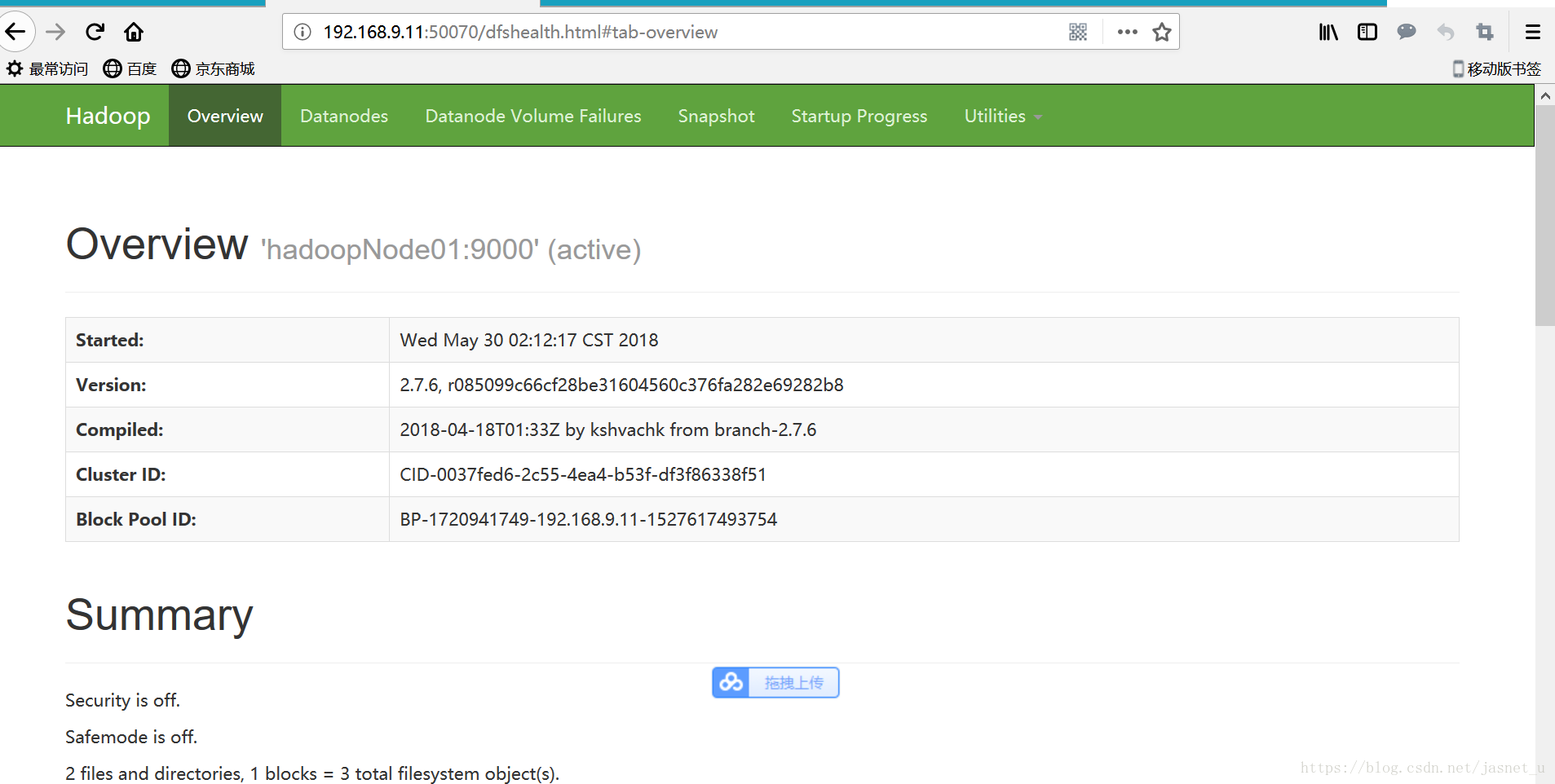
尝试访问 http://192.168.9.11:50070 查看hdfs集群 .
hadoop fs -put a.txt / 测试上传一个文件到hdfs根路径上
hadoop fs -ls / 查看 hdfs上根路径上的文件
hadoop fs -get /a.txt 下载hdfs根路径的文件
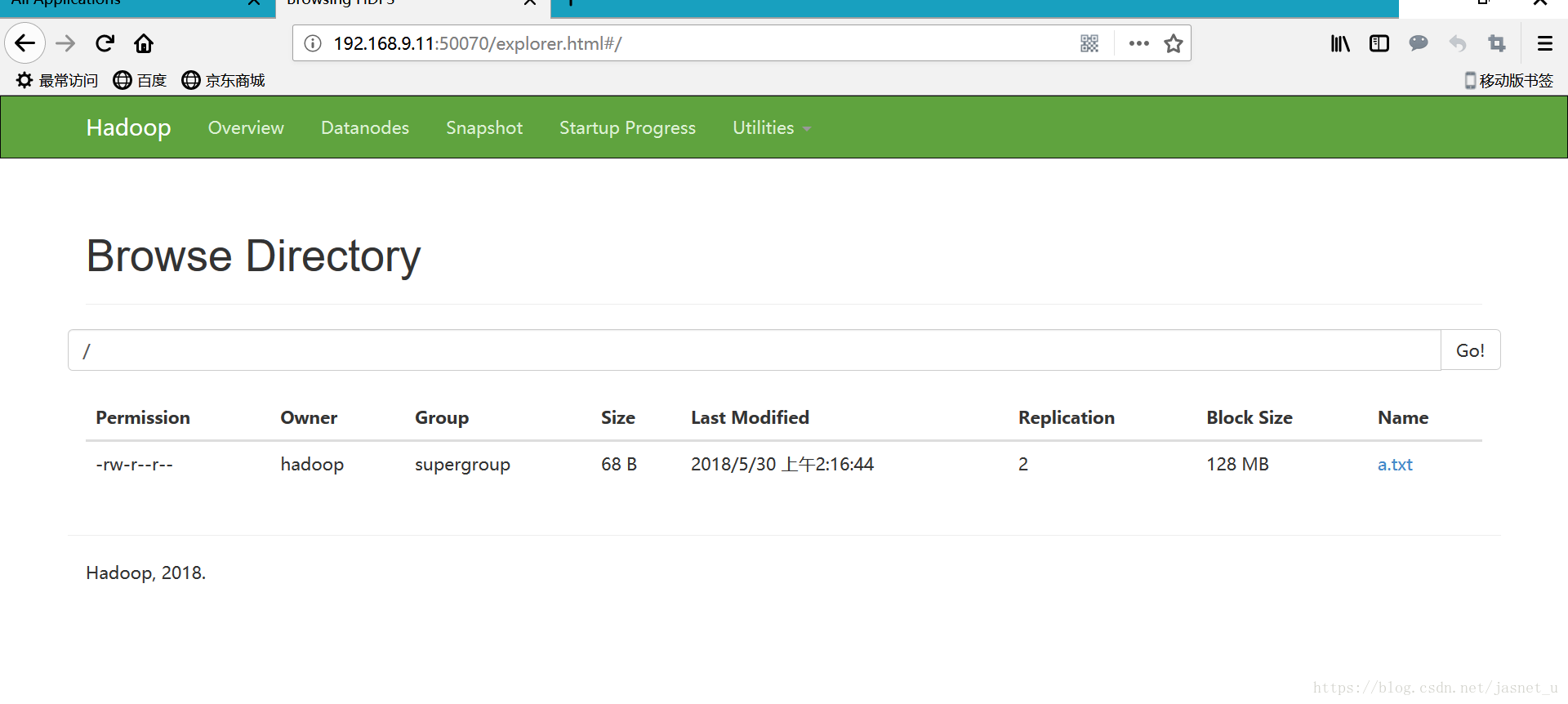
web网页上 Browse Directory 中也可下载hdfs中的文件(能下载成功)
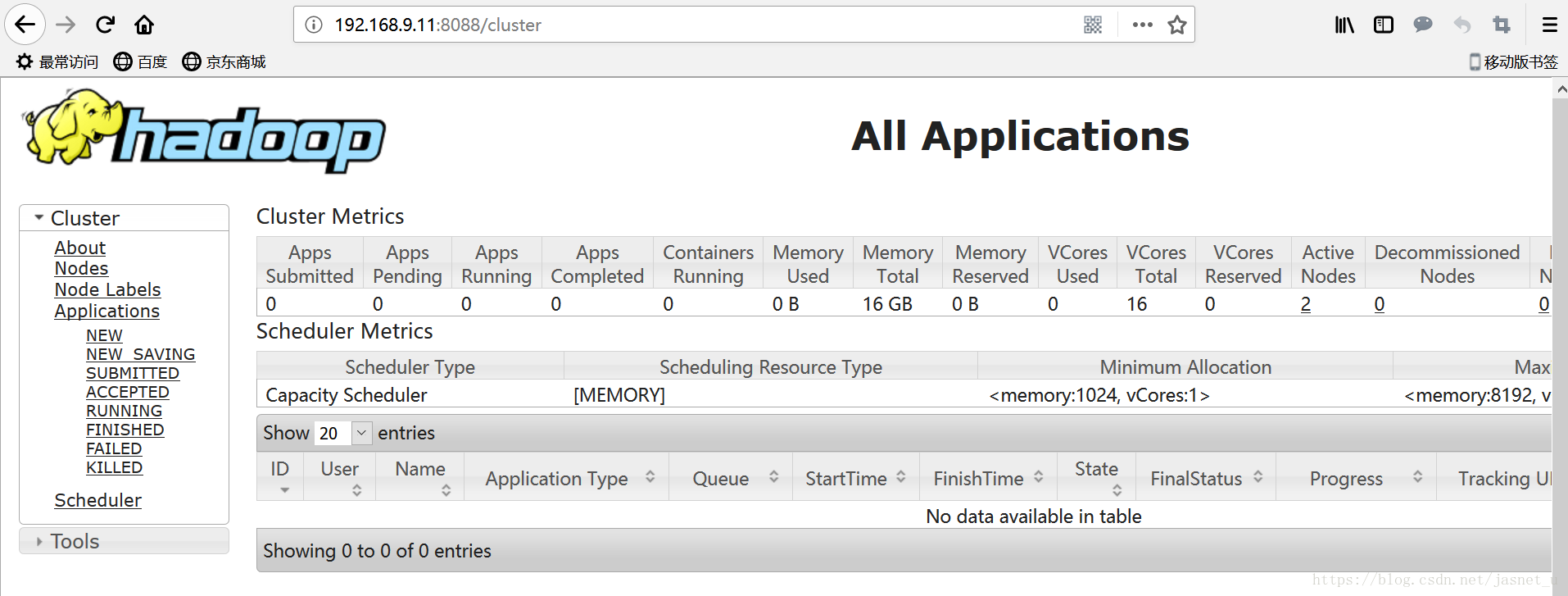
七、启动yarn集群
hadoopNode01 上执行:
start-yarn.sh 此命令会先启动本地的resourcemanager,在远程到hadoopNode02上启动nodemanager。
http://192.168.9.11:8088/
测试mapreduce 程序 (mapreduce程序打成jar包提交到yarn中执行)
hadoop jar hadoop-mapreduce-examples-2.7.6.jar pi 5 5 #计算圆周率

数据加载中,请稍候...
数据加载中,请稍候...
 阅读排行
阅读排行
数据加载中,请稍候...
数据加载中,请稍候...
