nodejs爬虫之node-crawler批量下载妹子自拍图 (原创)
作者: 朝如青丝暮成雪
发布时间:2018-03-11 22:41:16 文章分类:nodejs 阅读(2522) 评论(0)
发布时间:2018-03-11 22:41:16 文章分类:nodejs 阅读(2522) 评论(0)
本篇,我们介绍下nodejs领域中一个非常优秀的爬虫框架(模块)- node-crawler,相比我们上一篇自己手写的 request、cheerio,node-crawler支持更多的特性,比如 http代理,并发控制,连接超时设置,超时重试等。
node-crawler 源码
github: https://github.com/bda-research/node-crawler (拥有3500多个star,非常优秀的nodejs爬虫框架)
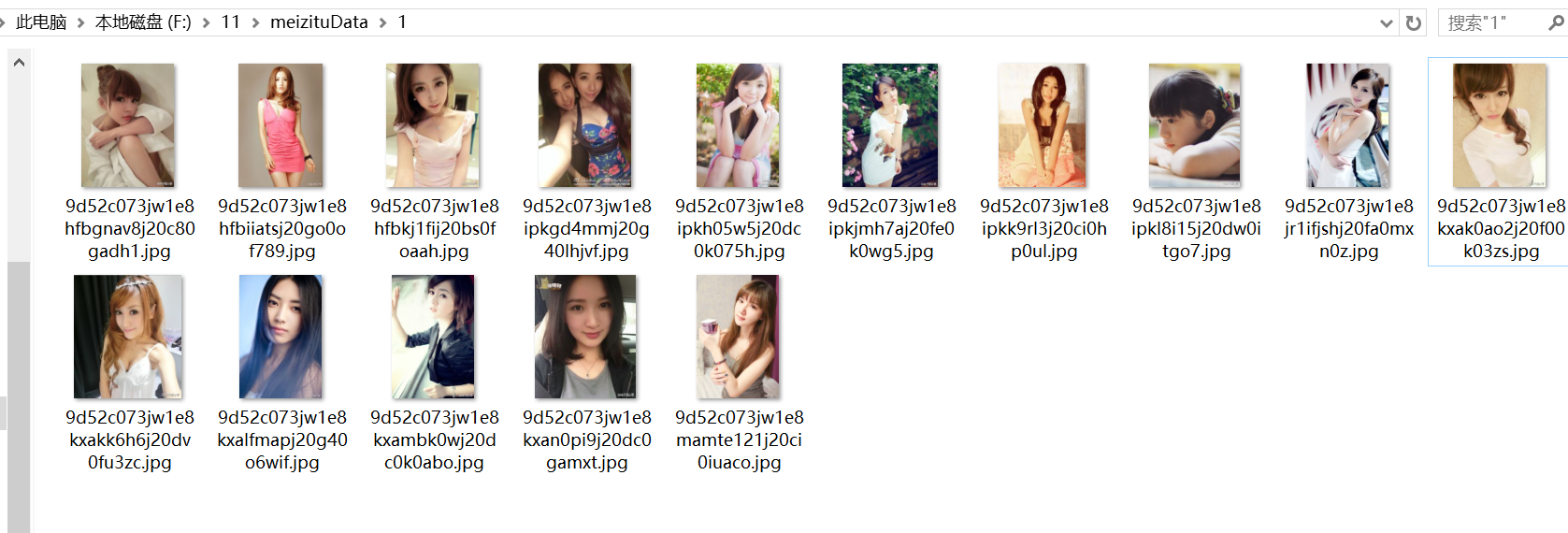
本篇,我们采用node-crawler 实现批量下载妹子图自拍照,保存到本地磁盘文件。
(当然,除了下载图片,下载音乐、视频等 node-crawler也是可以胜任的)
/**
* npm install crawler --save
* npm install cheerio --save
*
*/
var cheerio=require('cheerio');
var Crawler = require("crawler");
var fs=require('fs');
var baseUrl="http://www.mzitu.com/zipai/comment-page-"; // 1 2 .. 338
var saveDir="f:/11/meizituData";
//1 2 338 页
//爬虫 爬取网页
var crawler = new Crawler({
maxConnections : 10,
// This will be called for each crawled page
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
// $ is Cheerio by default
//a lean implementation of core jQuery designed specifically for the server
//console.log($("title").text());
console.log('pageNum:',res.options.pageNum);
var divArr=$("div.comment-body").toArray();
requestDownloadImg(divArr,res.options.pageNum);
}
done();
}
});
//请求下载图片到本地
function requestDownloadImg(divArr,pageNum) {
//爬虫对象 下载图片
var crawlerImg=new Crawler({
encoding:null,
jQuery:false,// set false to suppress warning message.
maxConnections:3,
callback:function (error,res,done) {
if(error){
console.log(error);
}else{
//var $=res.$;
//fs.createWriteStream(res.options.filename).write(res.body);
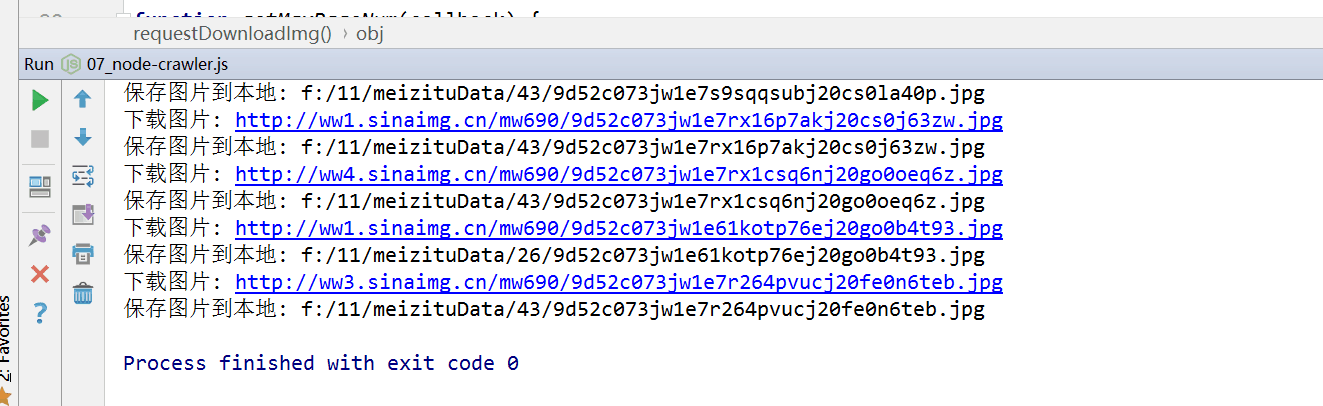
console.log("下载图片:",res.request.uri.href);
var pageNum=res.options.pageNum;
var filename=res.options.filename;
if(!fs.existsSync(saveDir+"/"+pageNum)){
fs.mkdirSync(saveDir+"/"+pageNum);
console.log("创建目录:",saveDir+"/"+pageNum);
}
fs.createWriteStream(saveDir+"/"+pageNum+"/"+filename).write(res.body);
console.log('保存图片到本地: '+saveDir+"/"+pageNum+"/"+filename);
}
done();
}
});
var imgArr=[];
for(var div of divArr){
var $=cheerio.load(div);
var imgUrl=$("p > img").attr('src');
var filename=imgUrl.substring(imgUrl.lastIndexOf("/")+1);
// console.log(imgUrl);
// console.log(filename);
//console.log("----");
var obj={
uri:imgUrl,
filename:filename,
pageNum:pageNum,
timeout:60000,//默认是15000
};
imgArr.push(obj);
}
crawlerImg.queue(imgArr);
}
//获取最大页码数
function getMaxPageNum(callback) {
crawler.direct({
uri: 'http://www.mzitu.com/zipai/comment-page-1',
skipEventRequest: false, // defualts to true, direct requests won't trigger Evnet:'request'
callback: function(error, res) {
if(error) {
console.log(error)
} else {
// console.log(response.statusCode);
var $=res.$;
var maxPage=$("div.pagenavi-cm > span.page-numbers.dots").next().text();
//console.log("最大页数:",maxPage);
callback(maxPage);
}
}
});
}
//爬虫 抓取
getMaxPageNum(function (maxPageNum) {
console.log("最大页数: "+maxPageNum);//最大页面 338
var urlArr=[];
for(var i=0;i<50;i++){
var obj={
uri:baseUrl+(i+1),
pageNum:i+1,
};
urlArr[i]=obj;
}
crawler.queue(urlArr);
});
暂无评论

数据加载中,请稍候...
数据加载中,请稍候...
 阅读排行
阅读排行
数据加载中,请稍候...
数据加载中,请稍候...
